A Webscraping Application using Rails 5 and Ruby 2.4.4
This is a webscraping applicaiton for my local running club who like to compile results from Parkruns where our local club members have visited.
The scraping is done in two stages: 1) there is an index site where the list of sites where results are available is held, and then 2) the app goes to each of these sites to get the information.
I’m using ‘Mechanize’ as my scraping gem: I started using Nokogiri but I found that I could not set headers to defeat anti-scraping measures using this, and found that Mechanize just works.
I started using Postgressql because MySQL was not accepted by Heroku, however due to problems with Heroku, I started hosting this on a cloud computer and just continued using Postgres.
I initially tried Heroku to host this. However the app times out because it has a lot to do before the view can be displayed - particularly a lot of http which are costly and unavoidable. I was not able to alter the http timeout on Heroku so I went to hosting this on a Digital Ocean Droplet, which obviously allows me to alter the timeout - and lets me learn about Capistrano, nginx, and all the other stuff that things like Heroku just does for you. After a lot of development, the site loads quickly now, but uses offline jobs to achieve this. I could not get offline jobs (Resque workers) to run on Heroku, so I never went back to this.
For testing, I set up a Sinatra server (hosted in a different Git repository) to serve up test assets in development and test modes, and I’m using the ‘vcr’ gem to replay it in test mode.
When put into production, I found I was getting a connection refused when making too many requests too quickly, I therefore broke the requests up into individual jobs which fire at 10 second intervals using Resque delayed job. This has made is more reliable and of course it still collects data if one job fails. I’ve got Resque-Schedule set up to do some database administration jobs for me in the background.
The app is database heavy and takes time to do the scraping. To optimise this I’ve collected all the data in a massive hash and then saved it all in one db transaction at the end instead of individual transactions. I do various age grade and age category positions allocations on the hash before saving, this is much faster than using active record saves individually.
It is hosted here
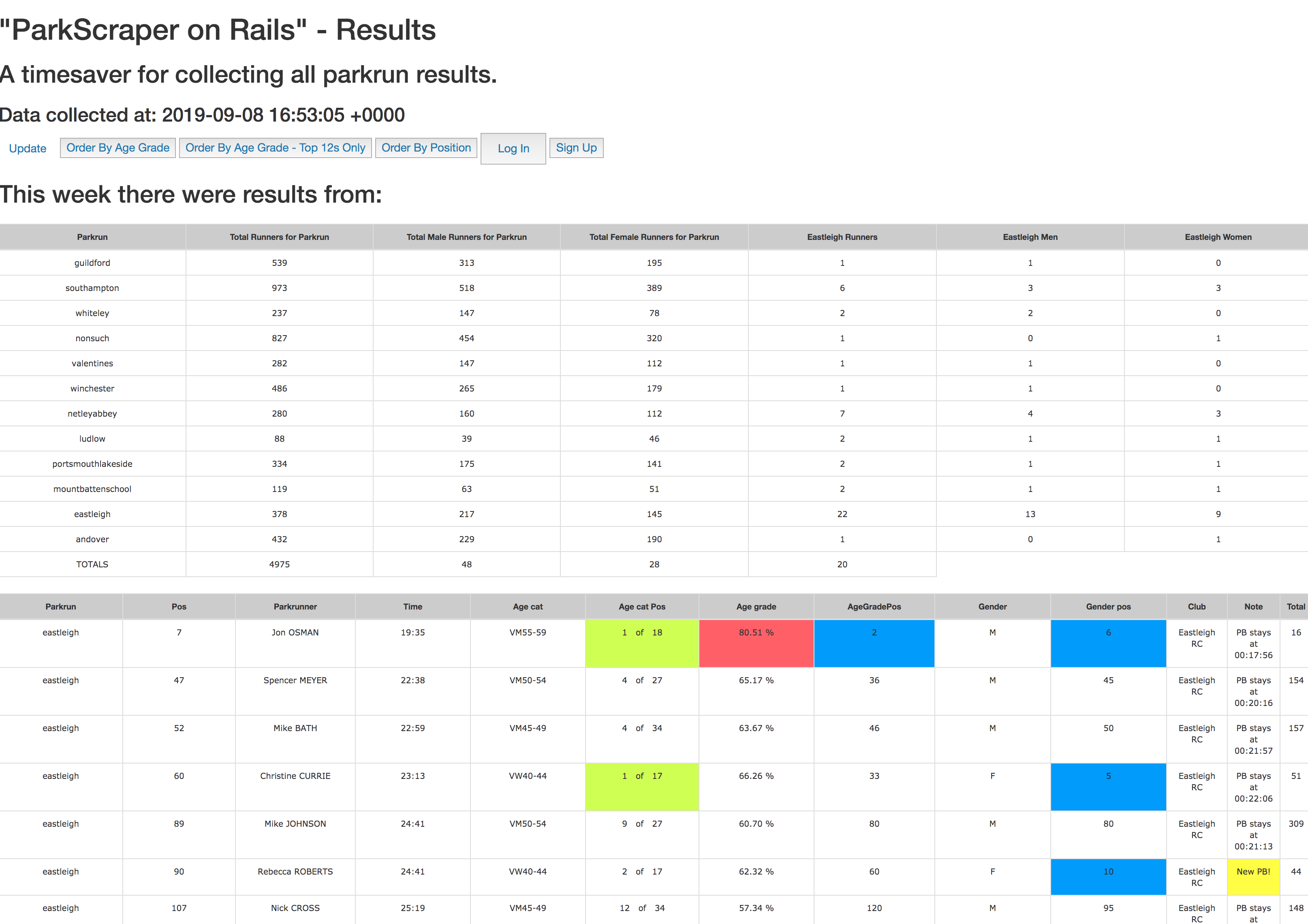
Here is a screenshot of the site: